31 Jul 2021
即便小時候深受《摩斯拉之歌》感動的我,從來都不是哥吉拉迷,甚至厭惡主流電影中哥吉拉的形象,招牌斯吼聲、各種腳色大亂鬥,很是乏味。但因著臉友的推薦,必須說,動畫《哥吉拉奇異點》把我心目中的哥吉拉感動帶回來了,從唱著《摩斯拉之歌》的小美人,疊代到讚嘆宇宙奧妙的《Alapu Upala》,以一種永恆回歸的形式辯證地返回、再現,啊,複雜而迷人的世界觀。

度規、時空幾何
劇中人物之間的對話,常有許多耐人尋味的討論,像是神野銘和李桂英在餐館裡關於意識、資訊與因果關係的蘇格拉底式對話、有川潤和加藤侍在葦原舊宅關於MD5編碼與時間關聯的討論、噴射傑格PP最後的自白,而葦原道幸的研究線索,神野銘和有川潤的通訊對話,更留下許多觀者能進一步挖掘的硬核素材。
許多葦原的研究筆記畫面以及洛桑會議紀錄,都說明了他很可能是一位精通廣義相對論與規範場論的研究者。站在葦原右側的A. Kerr很可能就是隱喻克爾度規(Kerr metric)的提出者R. Kerr。

愛因斯坦藉由等效原理,將適用於慣性坐標系的狹義相對論,推廣到適用於一切坐標系的廣義相對論,重力不再是力,而是時空彎曲的具體表現,而時空作為幾何整體的概念在局域具有閔可夫斯基度規(Minkovski metric)以及局域勞倫茲不變性(Local Lorentz covariance)。
時空(space-time)作為一體的概念是革命的,超越了牛頓力學時代時間、空間僅僅作為背景存在的世界觀,光速在任何觀察者看來都一樣的事實,具體展現了時空本身具有結構,在弱重力場條件下近似為閔可夫斯基度規。

神野銘在葦原位於英國的舊宅中翻閱筆記中一幕,出現了一條謎樣的方程式。
給定時空中的物質與能量分布,計算廣義相對輪中的愛因斯坦場方程式所得解,可以得知對應時空的度規,幾個著名的度規有:
前面葦原筆記中的方程式就是哥德爾度規,顯示他可能在研究如何進行時空旅行。然而人類作為具有實體物質型態的存在,要以肉身之軀回到過去,首先可能要通過被黑洞潮汐力撕裂的考驗。

但是佩羅2號做到了,如果有一天人類的意識可能被轉化為某種資訊存在,也許說不定可以用這樣的方式回到過去,再以某種形式與過去的自己溝通也說不定呢。

終戰、核爆
但如果搭著時光機回到二十世紀初期,日本人會想對自己的先輩說些什麼呢?

二戰以落在廣島和長琦的原子彈強制終局,核爆災難性的蕈狀雲深深留在人們腦海裡,初代哥吉拉誕生於終戰近十年後,故事設定哥吉拉受到核子試爆而覺醒,襲擊東京灣,當時世界局勢正是美蘇強國不斷進行氫彈試爆實驗的冷戰年代。
以前看過的《六度空間大水怪》中,意圖控制基多拉的壞蛋是由白人扮演,現在想來真是頗有意味在,有趣的是《哥吉拉奇異點》中,壞蛋看來也是白人扮演的,腳色設定也很多樣,有日本裔、南亞裔、華裔。
在神野銘的空想生物研究筆記中,出現一個人名叫安部公房,查了一下,是日本已故左翼文學家,他的小說感覺滿有趣的,有機會要找來看看。
規範場論、內在幾何
似乎存在著某種共時性,初代哥吉拉上映前一個月,對二十世紀理論物理學發展影響深遠的楊-米爾斯理論(Yang-Mills Theory)發表了。
「場」的概念從古典電磁學萌芽,空間中每個位置上可能存在著純量場、向量場、甚至張量場,而與廣義相對論並列為二十世紀理論物理學的兩大基石的標準模型(Standard Model),處理的就是場的運動變化,物質的運動與能量的轉化表現為場的波動,而最小單位的波動就是基本粒子,物質之間的能量傳遞表現為半整數自旋的費米子場與整數自旋的玻色子場的互動,前幾年CERN發現的希格斯粒子就是賦予費米子與W+、W-、Z0等規範玻色子「質量」概念的自旋為零的希格斯純量場。
楊-米爾斯理論的革命性在於拓展了原本量子電動力學所使用的阿貝爾框架,使用了非阿貝爾框架,開拓了豐富的理論發展空間,最終除了重力以外,電磁力、弱作用力與強作用力在二十世紀被統一在標準模型下。
標準模型 G=SU(3)xSU(2)xU(1)
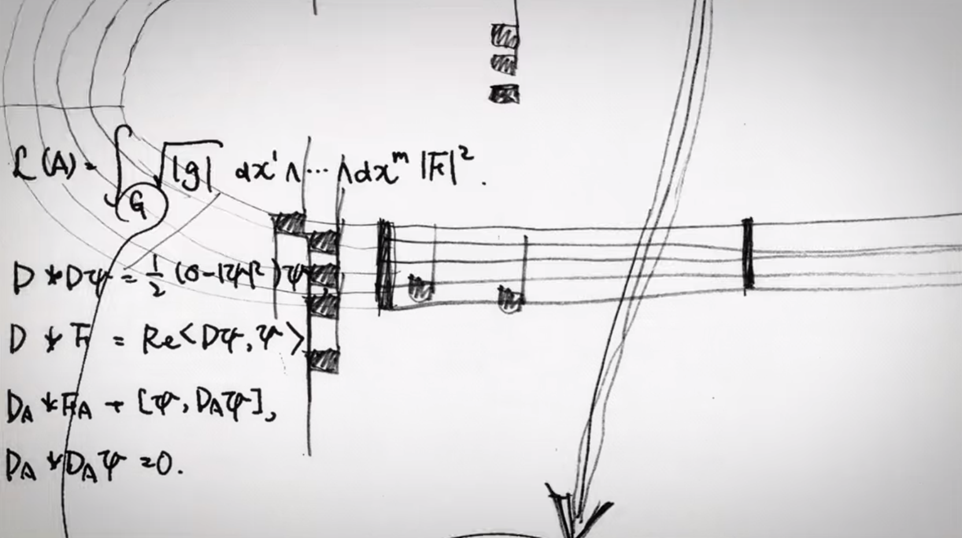
葦原筆記其中一頁寫著似乎是描述超導現象的金茲堡-朗道方程式(Ginzburg-Landau Equation)與其幾何結構密切關聯的楊-米爾斯-希格斯方程式(Yang-Mills-Higgs Equation)。看來葦原也研究過希格斯自發對稱破缺機制?
對稱、轉換
葦原筆記中還有兩個奇怪的句子和詞彙,”可怕的對稱”(Fearful Symmetry)與劇中能把高次元物質「紅塵」無效化的”正交對角轉換器”(Orthogonal Diagonalizer)。
前者似乎是取自華裔美籍物理學家徐一鴻科普著作名稱《可畏的對稱》。
物理學有個著名的諾特定理(Noether’s Theorem),指出每種對稱都有對應的守恆律,平移不變對應動量守恆、旋轉不變對應角動量守恆、時間不變對應能量守恆…等等,在方法論上,物理理論就是要找到能正確描述世界中對稱性的拉格朗日量(Lagrangian)。
由於對稱性在物理理論中扮演的重要角色,群論(Group Theory)研究變的非常重要,特別是李群(Lie Group),李群的不可化約表現(irreducible representation)和基本粒子有一定對應關係。

也許BB在尋找的,是類似能夠進行將質子轉化成中子的Beta正衰變(Beta+ dacay),抑或是不同粒子世代之間的轉換?
意識與自由
不斷自我更新的噴射傑格PP,在最後關頭想起自己來到這個世界的目的,說著
我在一開始就知曉一切,但卻想不起來。
即便身處於世界之中,卻不知道來到世界的目的,只能在「時間的洪流」中不斷地找尋存在的意義,人不也是如此。
累了嗎,聽首歌吧。
 《Alapu Upala》
《Alapu Upala》
宝(石)とされるもの
地と天
光 この場所
火と水
時間 この場所
永遠 理解され難いもの
沈黙とされるもの
統治者 風
心に決めること 対話
唯一であること 自由意志の行為
宇宙の現象のすべて 儀式
苦しみを取り去る者 与えること
不死 熱
見えない法則
集まり 大きな数字
真実 知性
歌詞出處
24 Jul 2021
偶然看到jservf老師的「你所不知道的 C 語言」系列講座,為我這個非科班出生的軟工給解惑了不少C語言方面的概念,其中印象最深刻的是”representation”這概念。
In C, everything is a representation (unsigned char[sizeof(TYPE)])
依據規範好的資料型態(資訊如何以bit的形式所表現),給定資訊所存的記憶體開頭位置以及所佔據的長度(幾個bytes),那麼資料就能被有效存取以及修改。
由於C語言只有傳值,所以呼叫函式時,應該傳遞資料所在的記憶體位置及型態資訊即可,而非資料本身的內容,但傳遞形式而非內容的作法,反過來要求程式撰寫者清楚知道自己在對記憶體做什麼處理。
除了資料可以儲存在記憶體中,函式本身也是作為資料被儲存在記憶體中被呼叫。caller呼叫callee時,也是把stack pointer指向記憶體中的函式所在的位置,也就是所謂的function pointer儲存值。
疫情期間,粗讀了ISO/IEC 9899, aka C99 standard,特別在語言與函式庫章節,對以往實作問題有了不少解惑,但還是有許多地方不是很了解,以後肯定需要偶而回去看看。
26 Feb 2021
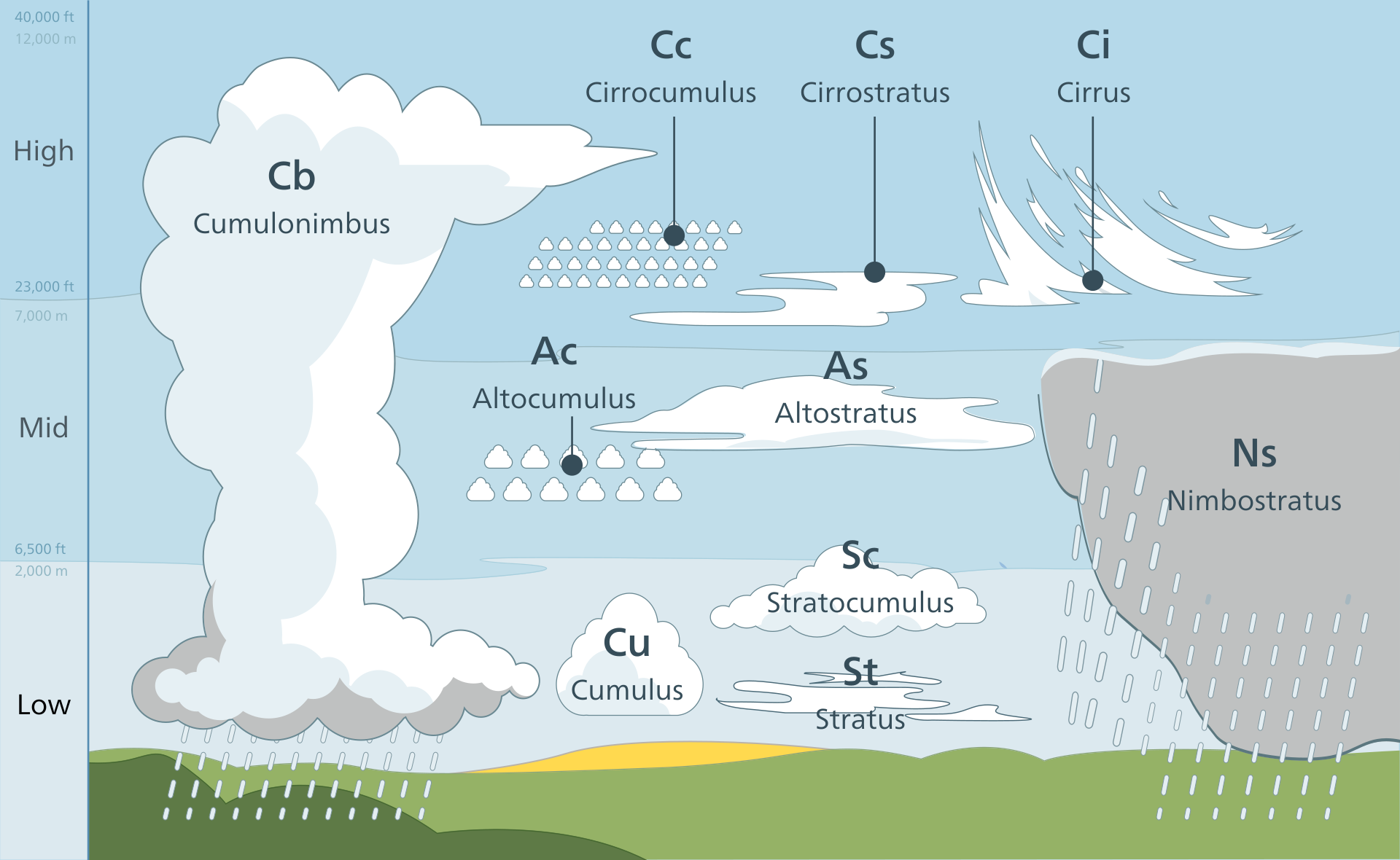 不同高度發展之各種雲狀。資料來源:wikipedia
不同高度發展之各種雲狀。資料來源:wikipedia
會下雨的雲主要是積雨雲(Cb)與雨層雲(Ns),前者導因於大氣中垂直對流旺盛,把下層水氣往上層帶凝結所致,發展範圍可從500公尺至對流層頂(中緯度處~10公里),後者可以是對流能量不夠強,以致衝不高所致,又或是伴隨著強烈對流系統出現之層狀降雨,發展範圍可從500公尺至5,500公尺。
參考資料: 收集水氣的濃積雲、雲的故事、wikipedia
氣象雷達(Radar)的主要目的為提供即時的、大範圍的降雨估計,透過發射S-band(波長~10cm)或是C-band(波長~5cm)的脈衝電磁波,偵測周遭空間水氣含量分布得回波強度dBZ後,進行Z-R關係式做簡單降雨估計或使用雙偏極化參數作更精確之估計。
給定空間中雨滴粒徑分布關係(Raindrop size distribution),透過電磁波散射矩陣計算(T-matrix),則可得雷達觀測所使用的Z-R關係式,然而問題是,不同的降雨系統如層狀降水(stratiform)與對流降水(convective)的雨滴粒徑分布有所差異,若使用同一組Z-R關係式進行降雨估計,則有高估或低估問題,因此如何掌握當下降雨系統的雨滴粒徑分布,即時修正雷達降雨估計計算,則是另一個課題,雨滴粒徑分布觀測資料是透過一種叫做雨滴譜儀(Parsivel)的觀測儀器得到。
參考資料:
Raindrop size distribution、
pytmatrix、
雨滴譜儀Parsivel2
使用wradlib套件繪製雷達訊號發射路徑與地形遮蔽
wradlib是一款可讀取雷達資料的python套件,與另一款常用的雷達資料處理套件pyart不同點之一在於,前者擅長讀取德國Selex雷達的rb5資料,後者則是美國NEXRAD雷達資料。
本文參考自wradlilb官網文章Beam Blockage Calculation using a DEM,給定雷達站經緯度與高度資料,結合數值地形模型資料(Digital Elevation Model),就可以畫出雷達訊號發射路徑及其受地形遮蔽情況(Beam Blockage)。
完整程式碼
使用資料
如前所述,為了繪製雷達發射傳播路徑與受地形遮蔽情況,需要雷達經緯度與高度資訊與數值地形模型DEM,前者網路上都能查到,或是googlemap就可估計,DEM可從美國地質調查局USGS下載,這裡使用30角秒資料(解析度25公尺~42公尺)。必須注意的是,地形資料並沒有包含建築物高度資訊。
繪製結果
S-band雷達,RCWF五分山雷達站
lon, lat, height = (121.782018, 25.071787, 766.0)
這裡僅顯示掃描範圍一百公里以內的雷達發射路徑與地形遮蔽資料,增加程式變數bins可增加掃描範圍。
從Beam Blockage Fraction可看到,五分山雷達很好的涵蓋了北北基桃和宜蘭地區一定的低空區域,然而較高設站高度(766公尺)雖然換取了更多有效掃描範圍,但也犧牲了較多1000公尺以下的觀測區域(僅於20km以內有效,且高於766公尺)。特別是宜蘭地區受地形遮蔽影響,較無法有效觀測蘭陽溪河谷中上游區域對流發展狀況,想必這也是為什麼氣象局希望在宜蘭設置降雨雷達了吧。
新聞 宜蘭居民反對設降雨監測雷達 氣象局:有在找備選地點
參考資料 : 終止七星山氣象雷達站的設置
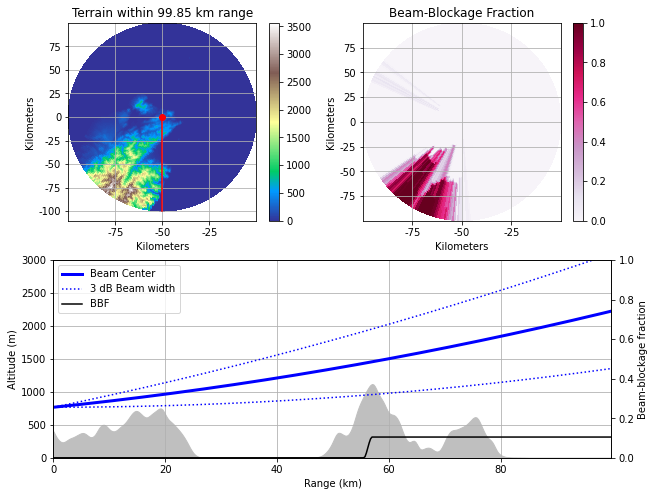 五分山雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
五分山雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
站在地球外來看,則會有下面這張圖,紅色線為水平線,綠色線為考慮電磁波被大氣折射所得水平發射路徑,藍色為雷達0.5度發射路徑,虛藍線為main lobe的3dB線,雷達主要發射能量都集中在main lobe上,上圖中黑線BBF為main lobe 3dB範圍內隨距離被地形遮蔽的比例。
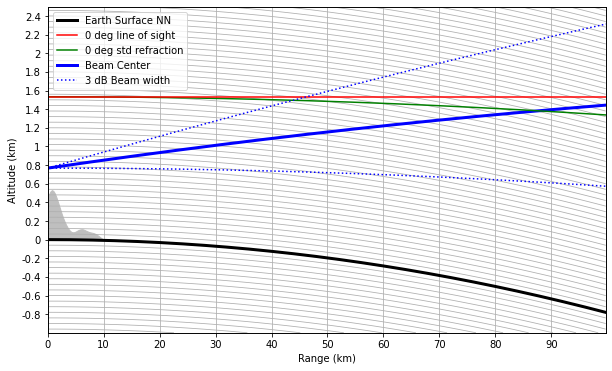 同前圖,考慮地球曲率後。
同前圖,考慮地球曲率後。
S-band雷達,RCHL 花蓮雷達站
lon, lat, height = (121.628372, 23.988536, 61.0)
西邊陡峭的中央山脈以及南南西方突兀的海岸山脈,使得花蓮雷達站肩負的主要任務不是觀測臺灣本島,而是東方太平洋海面的颱風動態,以爭取更早的預警時間。
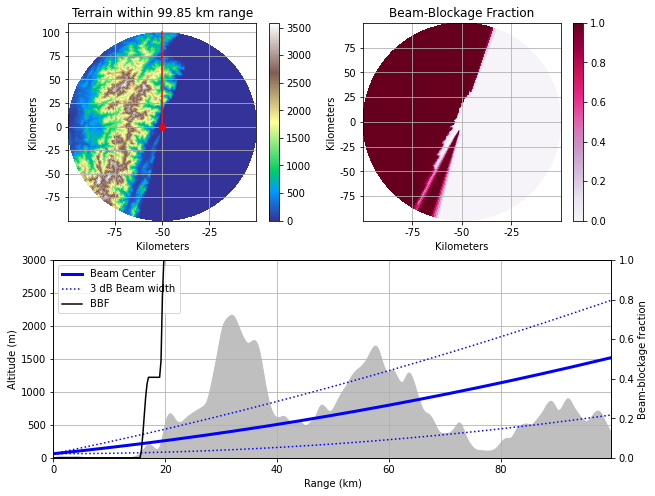 花蓮雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
花蓮雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
他曾協助興建氣象雷達站 50年後Mr. Hal Bogin來台重溫過往點滴
S-band雷達,RCKT 墾丁雷達站
lon, lat, height = (120.855609, 21.900181, 40.85)
從0.5度Beam Blockage Fraction來看,墾丁雷達站扮演的腳色與花蓮站相同,主要提供巴士海峽上的颱風動態。
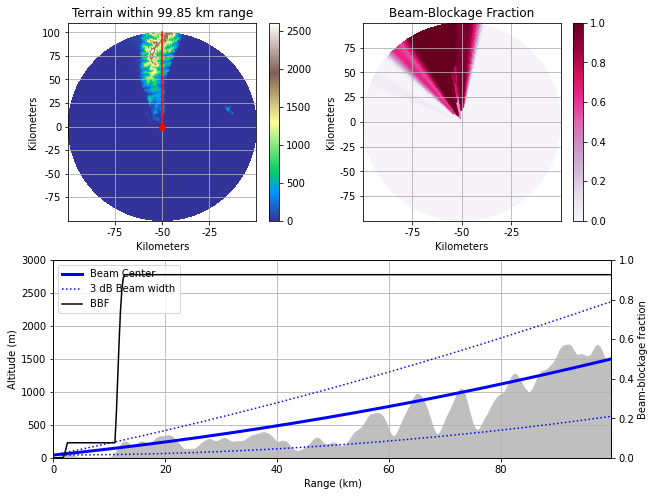 墾丁雷達站0.5度仰角發射路徑與所經地形遮蔽情形。
墾丁雷達站0.5度仰角發射路徑與所經地形遮蔽情形。
新聞 遊墾丁一定看過神秘「哈密瓜」!真實作用竟然是…
S-band雷達,RCCG 七股雷達站
lon, lat, height = (120.088978, 23.147402, 33.0)
由於七股居民抗爭,七股雷達站後續會牽涉到現址西北方海堤處。從Beam Blockage Fraction來看,七股雷達站為臺灣西半部提供了絕佳的地面天氣觀測,有效涵蓋從地面以上之觀測區域,對臺灣夏季西南氣流的降雨估計至關重要。
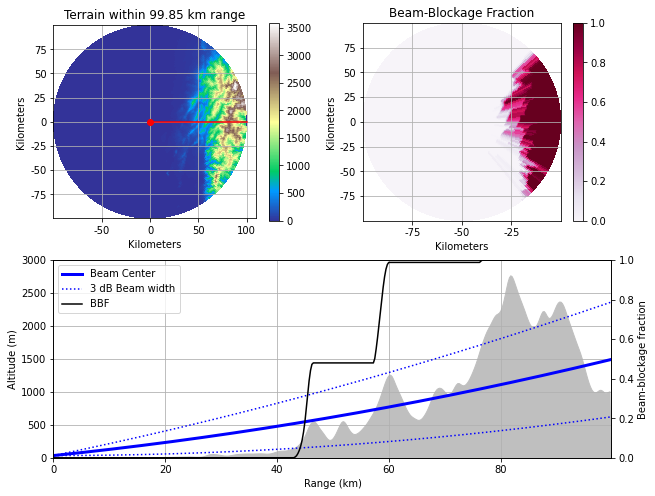 七股雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
七股雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
新聞 台南七股氣象雷達新站動土 可望成新地標
C-band雷達,RCSL 新北樹林雷達站
lon, lat, height = (121.400546, 25.003839, 290.0)
前面提到的4座S-band雷達是臺灣早先建立的雷達觀測站,主要提供大範圍降雨觀測,然而近幾年來短時強降雨等極端降雨致災事件發生頻率越來越高,後續政府針對都會地區防洪需求設置掃描頻率較高(每2分鐘)的C-band雷達,由於波長較短,對強降水區域更為敏感,但反過來說,有效觀測範圍也較小(150公里),分別於2017、2018、2019年啟用高雄林園、台中南屯、新北樹林防災降雨雷達。
參考資料:RADAR POLARIMETRY AT S, C, AND X BANDS
若將樹林雷達站與五分山雷達站的0.5度Beam Blockage Fraction相比,乍看五分山雷達有更好的有效涵蓋範圍,但如前所述,這是由於五分山雷達站蓋在七百多公尺的山上,在有效低空觀測區域來比,高度三百公尺左右的樹林雷達站明顯更勝一籌,在此認知下去看樹林雷達站的Beam Blockage Fraction圖,就會了解確實是非常優秀的選址地點,能有效涵蓋雙北最低三百公尺以上低空區域,東北方達基隆,西南方可監測桃園新竹都會區。
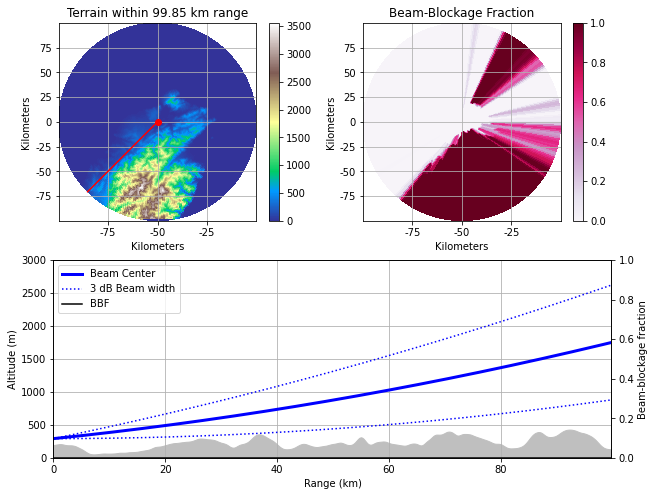 新北樹林雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
新北樹林雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
新聞 全台第3座降雨雷達於新北啟用!防災、淹水預警更精準
C-band雷達,RCNT 台中南屯雷達站
lon, lat, height = (120.579441, 24.144220, 293.0)
坐落於大肚山台地西南側望高寮的台中南屯雷達站主要肩負台中都會區防洪重任,觀測區域為東側市區上空與東方雪山山脈區域,南南東方可觀草屯、南投、集集等地上空,東北方可觀卓蘭、石岡、東勢山區降雨,能夠為大安溪、大甲溪、大肚溪、濁水溪中上游集水區提供更密集的降雨估計資料,為台中都會區及下游流域鄉鎮爭取防洪預警時間。
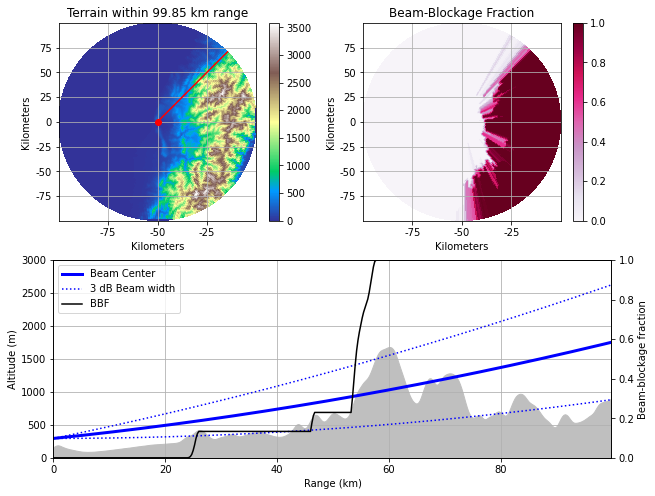 臺中南屯雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
臺中南屯雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
新聞 第二座防災降雨雷達 台中望高寮啟用
C-band雷達,RCLY 高雄林園雷達站
lon, lat, height = (120.380659, 22.526775, 153.0)
位於軍方林園營區的高雄林園雷達,則可監控高雄都會區以及高屏溪上游荖濃溪與隘寮溪之降雨情況。
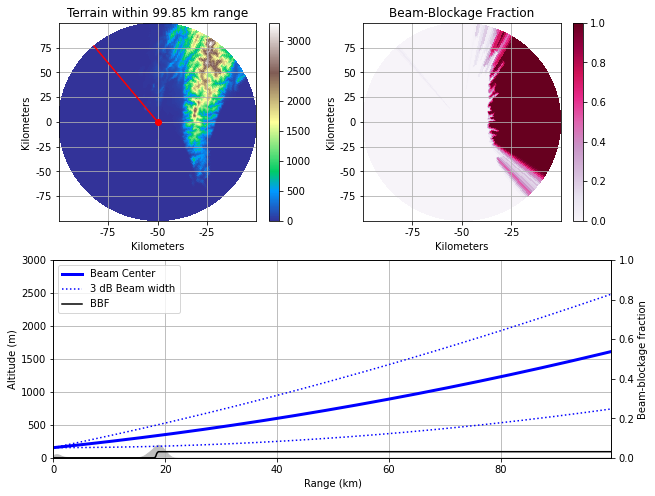 高雄林園雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
高雄林園雷達站0.5度發射仰角路徑與所經地形遮蔽情形。
新聞 防豪雨 氣象局南部防災降雨雷達啟用
回到一開始的問題,「雷達能看到多低的雲?」看到這裡想必已經能大概了解台灣目前七座氣象雷達能夠看到多低的雲了,取決於雷達高度、發射仰角及被周遭地形遮蔽的情況,還有雷達觀測波段對水氣的敏感程度也會影響。
那雷達可以看到多高的雲呢? 為什麼有時候衛星雲圖看的到雲,雷達觀測圖卻沒看到呢? 這又是另一個故事了…
enjoy :)
29 Jan 2021
前陣子在Coursera上學了“Probabilistic Deep Learning with TensorFlow 2”這門課,驚嘆Tensorflow Probabilty的威力,能同時估計資料不確定性以及模型不確定性,迫不及待來牛刀小試一下。機率迴歸方法在這裡有清楚的實作介紹,本文中相關程式碼亦參考自此。
使用資料
氣象局開放資料可透過API取得,授權碼註冊帳號即有,氣象局opendata使用說明。
這裡擷取局屬有人測站的資料,含有過去三十天測站每小時的氣象觀測資料,如測站溫度、測站相對濕度、測站氣壓等等。
資料格式為json,但礙於自身才疏學淺,找不到可以直接轉換的工具,只好暴力轉成Dataframe後使用,有
以板橋測站(466880)為例,就資料畫出過去三十天的溫度、相對濕度、測站氣壓、測站風速
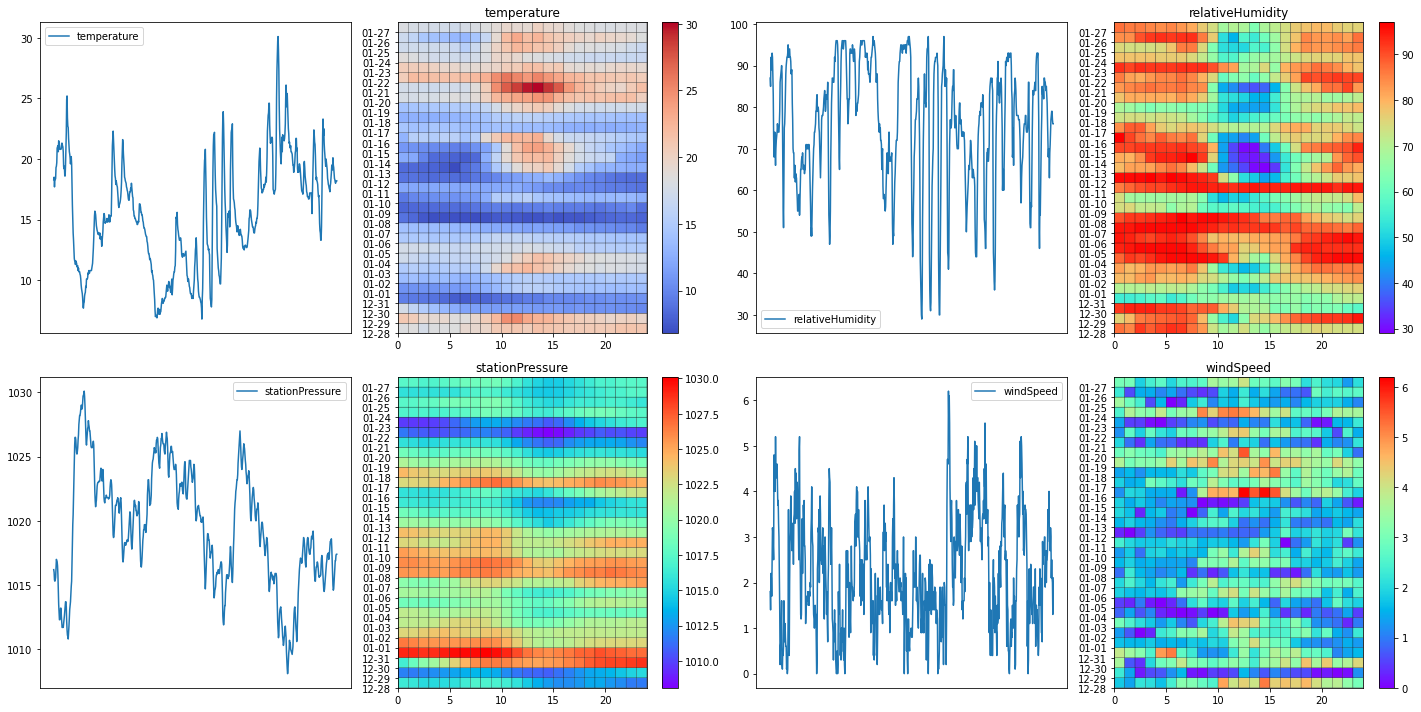 板橋測站過去三十日氣象觀測資料。由左至右、從上自下分別為溫度、相對濕度、測站氣壓、風速,小圖左為觀測資料依時作圖,小圖右為將觀測資料依日期、時間作格點圖。
板橋測站過去三十日氣象觀測資料。由左至右、從上自下分別為溫度、相對濕度、測站氣壓、風速,小圖左為觀測資料依時作圖,小圖右為將觀測資料依日期、時間作格點圖。
可清楚看到在1月8日寒流侵襲造成溫度驟降至10度以下,以及1月21日溫度回升至30度上下的情況。
若不考慮日期,只考慮溫度在每個小時的觀測值,可了解過去三十天中,小時溫度的分布狀況。
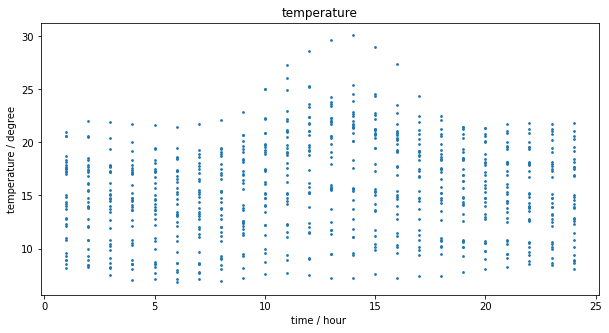 板橋測站過去三十日溫度觀測資料。小時溫度觀測值。
板橋測站過去三十日溫度觀測資料。小時溫度觀測值。
對小時溫度資料做機率迴歸分析
一般迴歸分析只擬合出具MSE最小的趨勢線,沒有估計預測值的不確定性,機率迴歸分析在擬合趨勢線同時亦給出預測值不確定性的估計值,這裡的不確定性指的是來自資料本身(Aleatoric),而非模型本身(Epistemic)的不確定性。
# 建立模型
encoded_shape = 1
model = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(256, activation='relu'),
tf.keras.layers.Dense(tfp.layers.IndependentNormal.params_size(encoded_shape)),
tfp.layers.IndependentNormal(encoded_shape)
])
# 訓練model時所用的 loss function - negative log-likelihood
nll = lambda y, rv_y: -rv_y.log_prob(y)
# 訓練模型
model.compile(optimizer=tf.optimizers.Adam(learning_rate=1e-4), loss=nll)
model.fit(x, y, epochs=2000, verbose=False)
與簡單迴歸分析不同的是,模型的最後一層使用了Probabilistic Layer,這層輸出的是一維正規機率分布。給定平均值與標準差,就可以決定正規機率分布,而機率層的前一層Dense layer,就是要去參數化平均值與標準差的所需參數。
另外,不同於一般訓練模型使用MSE作為loss function,這裡使用negative log-likelihood計算loss,back propagation來逐步調整模型的機率分布逼近訓練資料的分布。而其實MSE即是假設資料分布為Normal下所得到的約束結果,文章剖析深度學習 (4):Sigmoid, Softmax怎麼來?為什麼要用MSE和Cross Entropy?談廣義線性模型把這個關係講的很清楚。
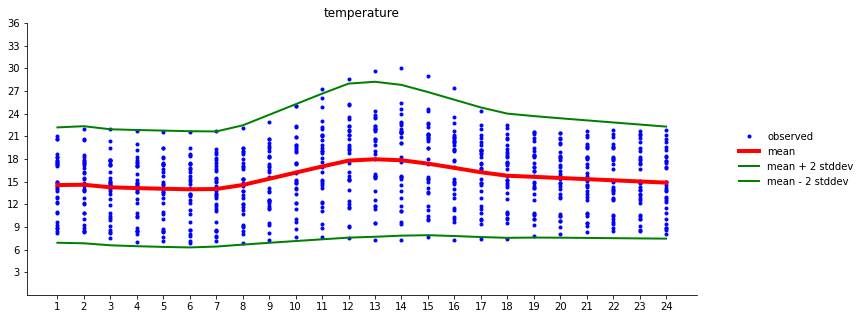 對板橋測站過去三十日溫度觀測資料小時溫度觀測值做機率迴歸分析。藍點為觀測值,紅線平均值,綠線兩個標準差位置。
對板橋測站過去三十日溫度觀測資料小時溫度觀測值做機率迴歸分析。藍點為觀測值,紅線平均值,綠線兩個標準差位置。
分析可見在清晨六、七點會是一天最低溫的最可能出現時間,這是由於地表熱能透過紅外線長波輻射逸散所造成(輻射冷卻),最高溫則發生在下午一點前後。從平均溫度值的斜率變化可粗略估計地表太陽輻射加熱效率、以及輻射冷卻降溫效率。
由於測站溫度會受到當時候大氣系統影響,偶而會出現一些較為極端的觀測值,特別在寒流來臨時更為明顯。
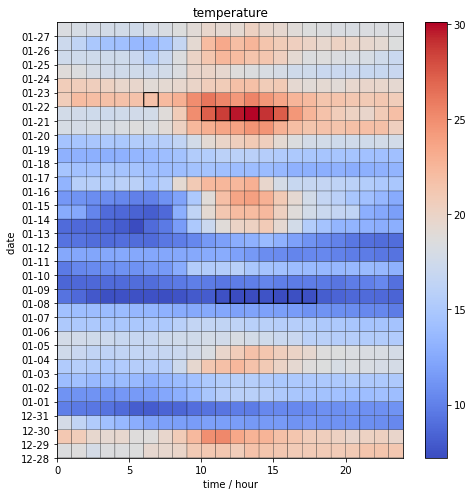 板橋測站過去三十日溫度觀測資料。小時溫度觀測值。黑框處為超過小時觀測值兩標準差以外的觀測值。
板橋測站過去三十日溫度觀測資料。小時溫度觀測值。黑框處為超過小時觀測值兩標準差以外的觀測值。
完整程式碼
enjoy :)
17 Nov 2020

如何訓練模型是一件事,在現實場景中應用模型又是另一回事。物聯網科技透過IOT技術連結各種電子儀器,若再賦予其AI演算法就朝智慧物聯網邁進一步了,而微控制器(Microcontroller)則是物聯網應用所乘載的關鍵實體元件之一,如何將訓練好的AI演算法有效部屬在MCU上,關乎實際運行時的效能。
ARM這篇2017年文章Hello Edge: Keyword Spotting on Microcontrollers以部屬KWS(語音喚醒)技術在MCU為例,探討在MCU上部屬AI演算法時可能遭遇到資源侷限與運算速度等實際問題,也對當時的KWS技術做了一些review,是可以學習到綜觀觀點的一篇優質文章。
這裡我嘗試依照ARM這篇教學文件Build Arm Cortex-M voice assistant with Google TensorFlow Lite,在colab上將預先訓練好的KWS模型部屬在STM32f746NG開發版上。
準備開發環境
安裝gcc-arm與相關套件
!sudo apt-get -qq update -y
!sudo apt-get -qq install -y xxd
!sudo pip -q install --upgrade mbed-cli
!sudo apt-get -qq install mercurial
!sudo apt-get -qq install -y gcc-arm-none-eabi
下載tensorflow repo
!git clone https://github.com/tensorflow/tensorflow.git
使用 mbed-cli + gcc_arm 編譯部屬
產出編譯MCU所需相關原始碼
%cd tensorflow
!make -f tensorflow/lite/micro/tools/make/Makefile TARGET=mbed TAGS="disco_f746ng" generate_micro_speech_mbed_project
下載MCU所需相關libray
%cd tensorflow/lite/micro/tools/make/gen/mbed_cortex-m4/prj/micro_speech/mbed
!mbed config root .
!mbed deploy
使用gcc-arm-none-eabi開始編譯相關檔案
!mbed compile -m DISCO_F746NG -t GCC_ARM
部屬執行檔到MCU,看看成果如何
cp ./BUILD/DISCO_F746NG/GCC_ARM/mbed.bin /你的MCU/
 LCD顯示MCU的KWS偵測結果一直為'unknown'。:(
LCD顯示MCU的KWS偵測結果一直為'unknown'。:(
實際執行發現,即使在沒有什麼背景噪音的情況下,會一直產出”Heard unknown”的訊息,而非應該產出的”Heard silence”,可能是演算法過於sensitive,又或者是MCU的的microphone有問題!? 而且必須靠近MCU版的microphone念出”no”字才有機會偵測到,並且偵測成功率很差,keyword “yes”則更慘,幾乎沒成功偵測幾個,之後debug方向,要嘛是MCU的micro有問題,要嘛是用的model真的太爛…
另一個安裝版本…
後來發現arm教學文件似乎參考的是這個github,照著readme.md上的說明也的確可以產出執行檔,部屬到MCU上後,發現反而才是教學文件中所使用的code…
一樣安裝相關套件
!sudo apt-get -qq update -y
!sudo apt-get -qq install -y xxd
!sudo pip -q install --upgrade mbed-cli
!sudo apt-get -qq install mercurial
!sudo apt-get -qq install -y gcc-arm-none-eabi
import repo
!mbed import https://github.com/uTensor/tf_microspeech
編譯、部屬
%cd tf_microspeech/
!mbed compile -m DISCO_F746NG -t GCC_ARM --profile=tflm/tensorflow/lite/build_profiles/release.json
這個版本中,偵測結果訊號只走usb回傳,LCD螢幕不會顯示偵測結果,可以用gtkterm以baud rate 9600讀取
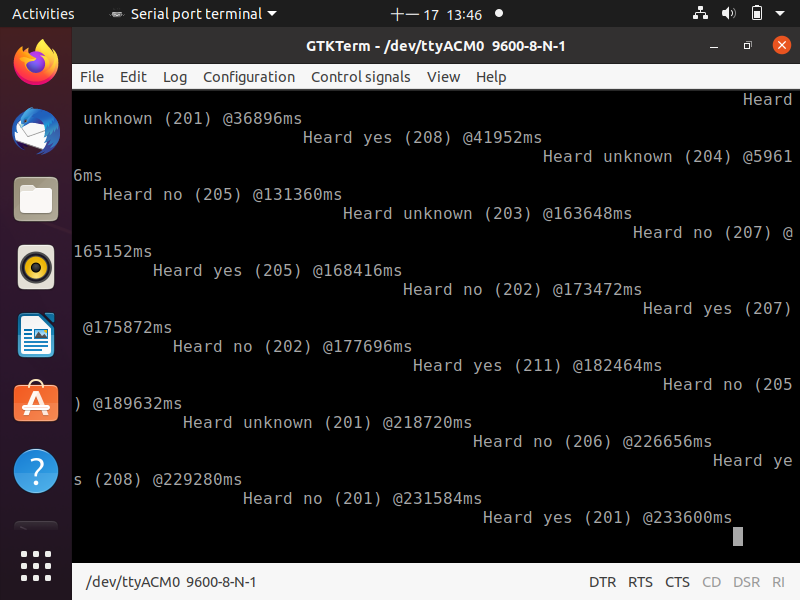 透過usb讀取MCU回傳KWS模型偵測結果。
透過usb讀取MCU回傳KWS模型偵測結果。
結果這個版本的偵測效果非常的好!輕聲說出yes或no也能偵測的出來 :D 看來可能是model的問題比較大,但因為是部屬到mcu上,從聲音訊號的擷取到最後模型偵測結果,中間任何library使用錯誤都可能導致結果不如預期,但至少可以確定的是,我的MCU上的microphone沒有問題 :D
透過usb讀取MCU回傳KWS模型偵測結果'yes'。
 透過usb讀取MCU回傳KWS模型偵測結果'no'。
透過usb讀取MCU回傳KWS模型偵測結果'no'。
若要加上螢幕顯示偵測結果可以參考ARM教學文件章節”Extend the program”去修改程式碼command_responder.cc,並將LCD相關libray與header複製到目錄tf_microspeech底下
%cp -rf /content/tensorflow/tensorflow/lite/micro/tools/make/gen/mbed_cortex-m4/prj/micro_speech/mbed/LCD_DISCO_F746NG* /content/tf_microspeech/.
重新編譯後部屬即可!
%cd /content/tf_microspeech/
!mbed config root .
!mbed compile -m DISCO_F746NG -t GCC_ARM --profile=tflm/tensorflow/lite/build_profiles/release.json -v
enjoy! :)